经过几十年的监管努力,我国质量安全的底线保障已铸造得相当牢固。虽然也偶有质量安全事故爆发,但却更多的表现为概率性的事件。怎么理解概率性的事件?作个类比,譬如交通事故的发生,我们就认为是概率性的事件:可以尽最大力量却预防和保障,但是无法准确预测更无法彻底杜绝。单纯从概率论的角度来看,质量安全的治理就比交通安全治理要好得多。一方面我们可以比较事件发生的概率,消费者只要参与消费,使用消费物品,就有可能发生质量安全事故;同样司机或行人只要出行,就存在一定发生交通事故的概率。相比而言,人们跟物品互动的次数明显比出行的次数多很多,也就是质量安全事故发生的基数会比交通事故大得多,而实现中质量安全事故的发生次数却比交通事故要少得多,因而质量安全事故的发生概率比交通事故要低很多。另一方面,我们可以从事故造成的社会伤害与损失的统计来比较,每年因交通事故而伤亡的人数,明显也比质量安全事件的多得多。所以说,如果我们接受交通事故是概率性的事件,就没有理由不接受质量安全也是概率性的事件。
那么,对于概率性的质量安全事件,我们先前的应对方式是怎样的呢?统计性的抽检抽查,就是物品有100个,随机抽样1个进行检测,检测通过则全体通过。而概率性的事件同样也可能只在这100个之中仅有1个存在风险。那么我们传统方式发现风险的概率是多少呢?不是百分之一,而是近乎百分一的百分之一,是万分之一!所以说我们传统的方式是以概率性抽样的方式来应对概率性发生的质量安全事件,其实是存在非常大的风险缺口的。
面对传统方式存在的监管风险缺口,大数据无疑是个非常有效的工具。从理论上来讲,大数据不是随机的抽样,是全体的样本。如果能够合理地运用大数据,对整体的物品进行全样本的数据覆盖,那么对于小概率发生的质量安全事件也能够进行准确的控制与监测。即便退一步来讲,可能现实条件或应用技术不能实现100%的数据覆盖,但是如果尽可能地覆盖更多的样本,发现概率性事件的机会也会多很多。所以从理论上来讲,应用大数据来进行质量安全监管是可以在很大程度上弥补传统方式背后的风险缺口的。
可是在实践中可以实现吗?我们专门研究了2008年的三鹿奶粉事件。我们相信如此大规模的质量安全事故是不可能毫无征兆突然暴发,所以我们打算通过互联网来找寻线索。基于深度网公司的平台,我们通过设定关键词,在互联网上定向搜索了与08年三鹿奶粉事件相关的信息,并进一步通过人工的剔除与筛查,最终确定了事件爆发前的信息分布,如图1所示。
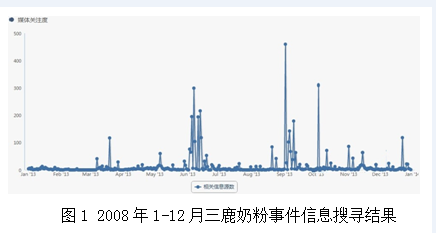
对风险信息进行时间序列的分析可以发现,网络上最早关于三鹿奶粉事件的信息呈现出现在2007年底;在2008年3月份,南京一家儿童医院的检验引起了不少媒体报道与消费者关注;到了2008年5月底6月初,网络上的信息大幅度增长,其中天涯论坛中的一篇题为“这种奶粉能用来救灾吗?!”的帖子,掀起了网络关注的高潮;9月份央视媒体首次报道“甘肃14名婴儿因食用三鹿奶粉同患肾结石”,事件全面爆发。当然这其中还有许多相关的风险信息,我们选取一些有代表性的结点,结合风险控制的一般流程与方法,进一步地可以绘制如图2所示的风险发展态势及过程控制图。
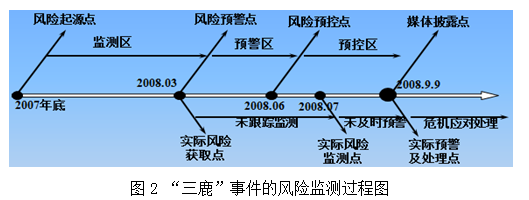
从图2中我们可以清晰的看到,早在2008年3月份时,通过网络信息的定向监测,完全可以进行风险预警;同时在6月份,大量的网络质量风险信息发布后,应当采取相应措施进行积极预防控制与应对。我们的监测结果相比实际危机事件在9月份全面爆发而言,是可以做到提前3-6个月的预警的。也就是说,如果当时我们的监管关注了互联网上消费质量发布的质量信息,是可以对“三鹿”事件进行有效地提前控制的。即便退一步来讲,互联网信息的真实性有待考证,但是当有一定数量信息指向同一种质量安全风险时,也可以对我们监管抽检抽查给予方向性的指导,对这些网络上反映的风险产品进行实际检测,以确定真伪。
因此,大数据对质量安全的治理,以整体数据覆盖概率性的质量安全事件,不仅仅只是一句理论上的口号,而在实践中是可以得到实证与实现的。
